The Architecture questions nobody asks before deploying AI agents

Most teams go straight to the demo. Here's what gets missed, and what it costs you.
There's a pattern playing out across enterprise AI right now that's almost too consistent to be coincidence.
A team identifies a promising use case for an AI agent. The proof of concept is compelling. Leadership gets excited, budget gets approved, and the project moves into delivery. Six months later, something has gone quietly wrong. Not a model failure. Not a capability gap. An architecture failure. The kind that's expensive to fix and almost entirely predictable.
The conversation around AI agents is dominated by capability questions: what can it do, how accurate is it, which model should we use? These are reasonable questions. They're just not the ones that determine whether an agentic system survives in production.
This post is about the questions that do.
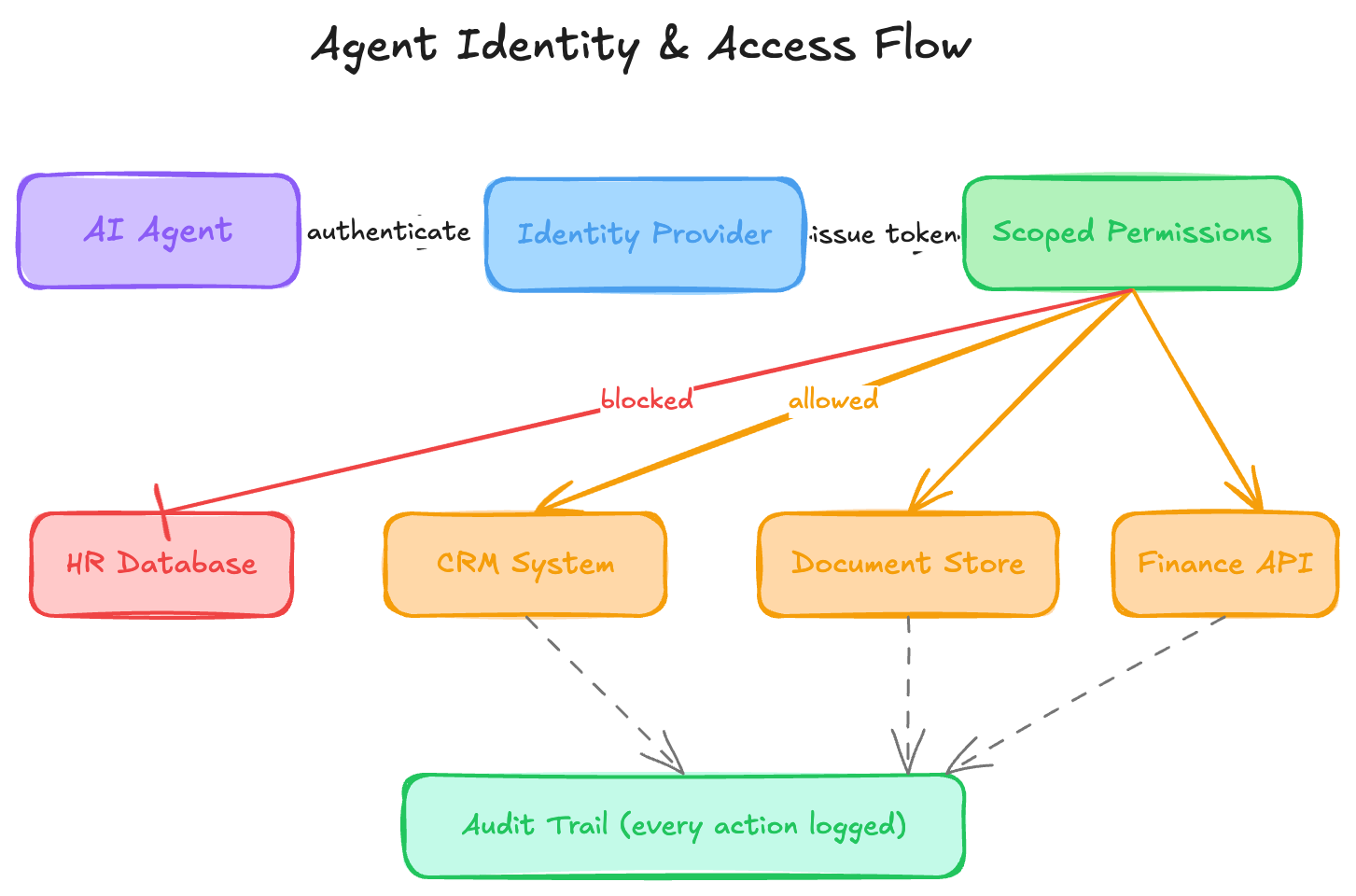
1. Who is this agent?
When a person acts on behalf of an organisation, we give them an identity. A badge. A login. A set of permissions that reflects what they're allowed to do, and a trail that records what they did. We don't hand a new employee a master key and say "use your judgement."
We do this with AI agents constantly.
Agents act autonomously, often across multiple systems, often with elevated access, because that's what makes them useful. But that autonomy requires a defined identity, scoped permissions, and an audit trail that can satisfy both your security team and, increasingly, your regulator.
The question to ask before you build: if this agent takes an action, can you tell exactly what identity it used, what permissions it had, and why it was allowed to do that?
If the answer is "we'll sort that out later," you're building technical debt into the foundation.
2. What does it actually know, and how do you know it's right?
Agents are only as good as the data they operate on. This sounds obvious. It isn't, in practice.
Most enterprise data environments are a patchwork: systems built at different times, maintained by different teams, with different definitions of the same fields and no single source of truth. Humans navigate this through context, experience, and the ability to sense when something seems off. Agents don't have that.
What they have is confidence. An agent operating on fragmented, unverified data doesn't fail loudly. It produces answers that sound authoritative and happen to be wrong. By the time you notice, the problem has compounded.
Data readiness for agentic AI isn't about having clean data. It's about having data with provenance. You need to know where it came from, when it was last updated, who owns it, and what it's authoritative for. Without that, you're not deploying an intelligent system. You're deploying a very confident one.
The question to ask before you build: can every data source your agent touches tell it when the data was last verified, and by whom?
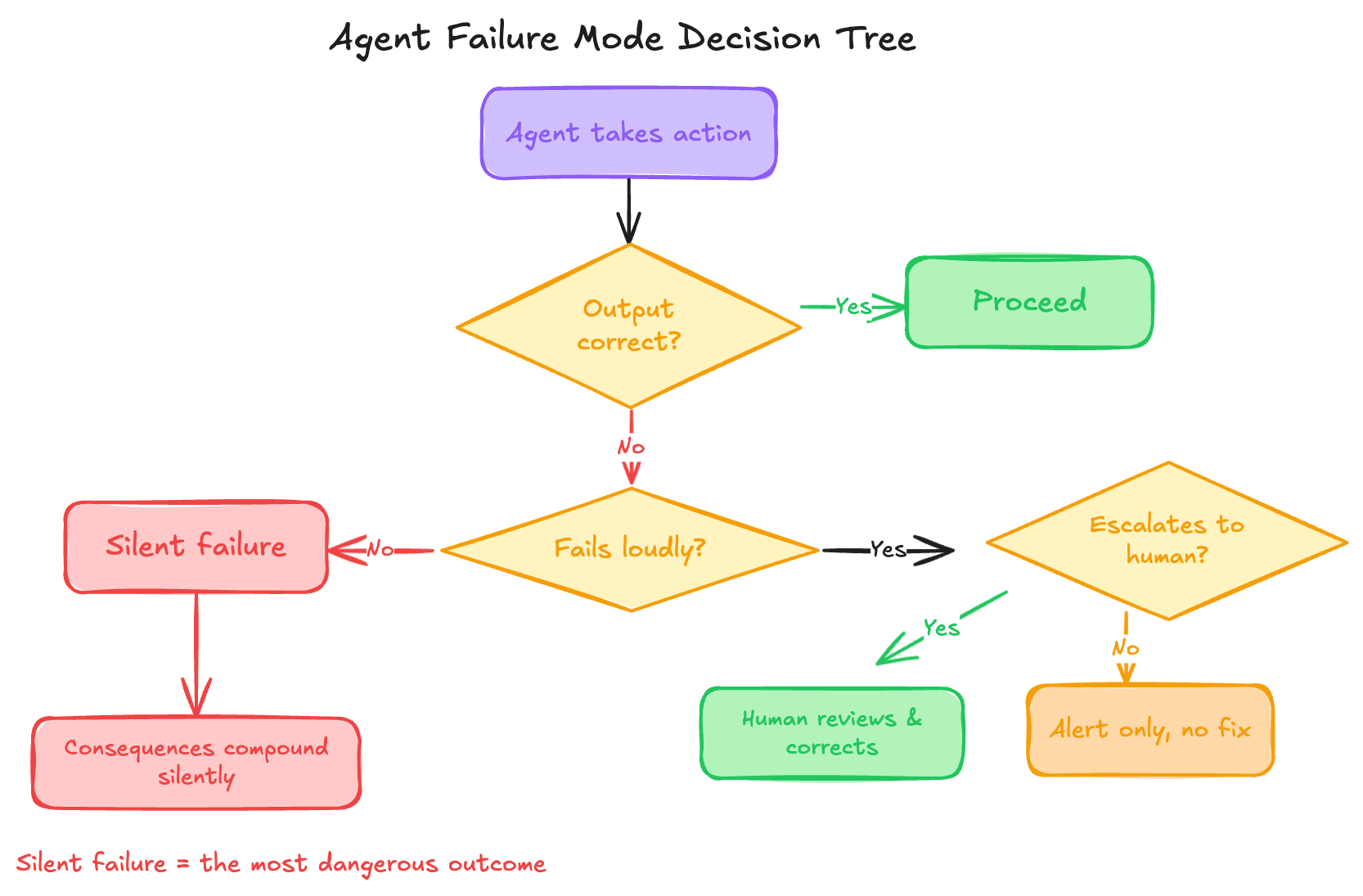
3. What happens when it's wrong?
Not if. When.
Every system fails. The architecture question isn't whether your agent will make a mistake. It's what happens next. Does it fail loudly, surfacing the error immediately so a human can intervene? Or does it fail quietly, continuing to act on a flawed premise while the consequences accumulate?
Most agent designs have no deliberate answer to this question. Failure modes are an afterthought, discovered in production rather than designed for upfront.
A well-architected agentic system has explicit answers to three sub-questions: how does the agent know it's uncertain, what does it do when it is, and who gets notified?
4. Who pays for this at scale?
Proofs of concept run on enthusiasm. Production is different.
Agentic AI is inference-heavy by design. Agents don't make one call to a model. They reason, plan, retrieve context, call tools, and often loop. At small scale, the costs are invisible. At production scale, with hundreds or thousands of concurrent agent sessions, they compound fast.
The question to ask before you build: has anyone modelled what this costs at 10x load, or at 100x? Not as an estimate, but as a constraint that shapes the architecture.
This means thinking about model selection at the task level (not every subtask needs your most capable model), caching strategies, and what your unit economics look like per agent action. Teams that skip this step don't discover the problem until they're committed to an architecture that's economically unsustainable.
5. Who owns it when something goes wrong?
Agents blur the lines of ownership in ways that organisations aren't used to.
When a human employee makes a costly mistake, accountability is relatively clear. When an AI agent does, acting autonomously, across systems, on behalf of multiple stakeholders, the question of who owns the outcome is surprisingly murky. Is it the team that built it? The team that uses it? The data team that provided the context it acted on? The vendor whose model it runs on?
Without clear accountability defined upfront, you get organisational finger-pointing at the worst possible moment, when there's a live problem that needs someone to own it.
The question to ask before you build: if this agent causes a significant error, who is responsible for identifying it, communicating it, and fixing it? Write it down. Get agreement. It's a boring conversation to have in week one and a critical one to have avoided in month six.
6. How does it fit into what already exists?
The hardest part of enterprise AI isn't the model. It's the plumbing.
Enterprise systems weren't designed to be called by an autonomous process. Authentication flows assume a human on the other end. APIs have rate limits built around human interaction patterns. Downstream systems have no concept of an agent as a caller type. Legacy integrations behave unexpectedly when hit at agent speed and volume.
This is where most enterprise AI timelines blow up, not in the model layer, but in the integration layer. And unlike model problems, integration problems don't reveal themselves in a demo. They reveal themselves under load, in edge cases, when the agent encounters a system state nobody anticipated.
The question to ask before you build: have you mapped every system this agent touches, validated that it can authenticate correctly, and understood how those systems behave when called autonomously at scale?
What this looks like when it goes wrong
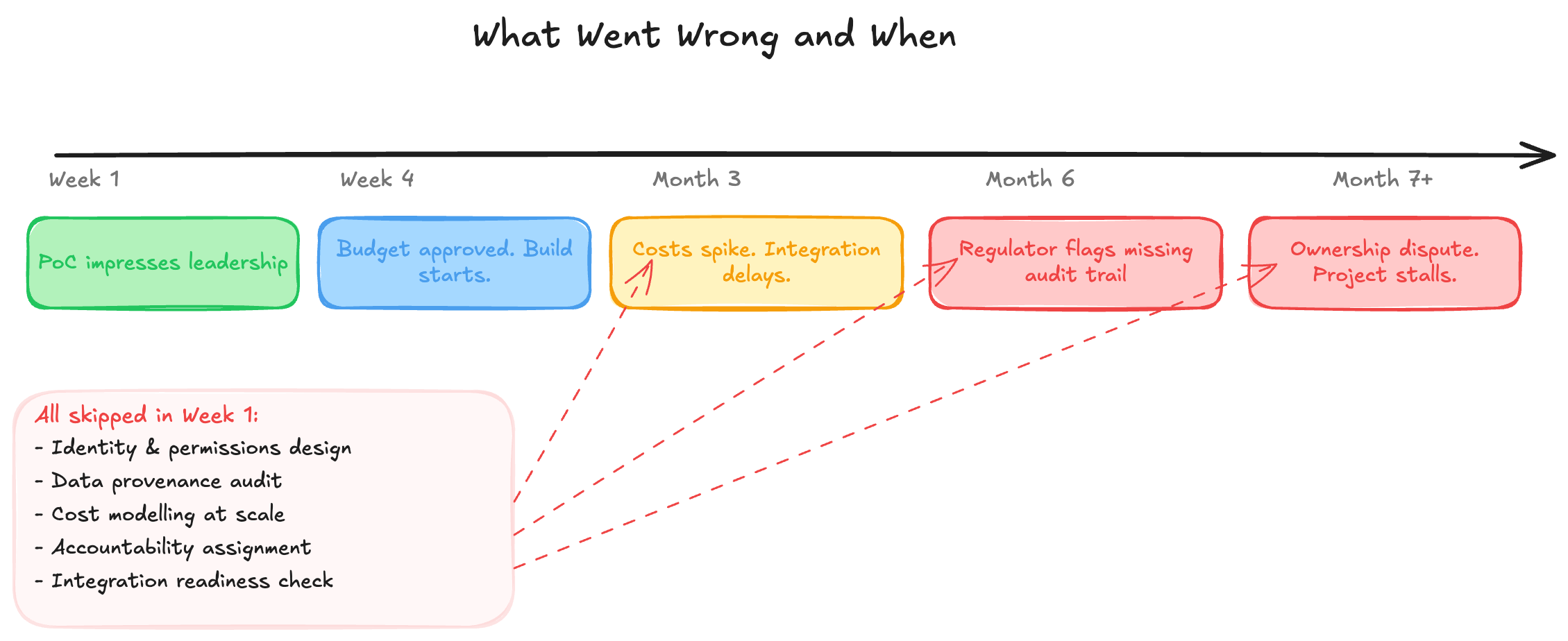
Consider a mid-sized financial services firm that deploys an internal AI agent to automate a document-heavy compliance workflow. The proof of concept impresses the right people. Budget is approved. Six months later:
The agent is making decisions based on data it has no way to verify is current. Two of its sources update on a 48-hour lag that nobody documented. There's no audit trail that satisfies the regulator's requirements, because identity and logging were planned as a phase two item. Inference costs are running at three times the projection because the architecture wasn't modelled at production load. And when the compliance team flags an error, the engineering team, the data team, and the vendor all point at each other, because ownership was never defined.
None of these are model problems. Every one of them is an architecture problem. Every one of them was predictable.
The pattern worth noticing
These six questions have something in common: none of them are interesting to answer in week one. Identity and governance feel bureaucratic. Data provenance feels like a data team problem. Cost modelling feels premature. Accountability feels like something to sort out when there's actually something to be accountable for.
That's exactly why they don't get asked.
The organisations that get agentic AI right in 2026 won't necessarily have the best models, the biggest budgets, or the most ambitious roadmaps. They'll have asked the unglamorous questions early, and built systems on the answers.
If you're working through an agentic AI initiative right now, a useful exercise is to run these six questions past your current design. Not to find reasons to slow down, but to find the gaps while they're still cheap to close.
If you find yourself stuck on more than two of them, it's worth a conversation before you build further.
